“What can we make with these?” How multimodal interaction could transform the way human translators work and live
Multimodal interaction – the essence of interactive translation dictation – has taken me, literally, around the world: from Glasgow to Tokyo, from Istanbul to Seattle. Among the many perks of having been part of the ICMI community for several years was an escorted VIP tour of Microsoft Research just outside of Seattle (USA) in 2015, including a visit to their Envisioning Centre.

I was able to see with my own eyes (and operate with my own voice and hands) the various prototypes you can see in this video. The Centre “is all about imagining how technology could be used to make life easier and more enjoyable, sometimes in small ways and sometimes in revolutionary ones.”
Inside this Envisioning Centre, multimodality is all around. Among the expected (and demonstrated) advantages of multimodal systems is indeed an easier and more enjoyable interaction with the technologies we use to live, work and play.
What is multimodal interaction?
For me, multimodal interaction means multiple ways of interacting with computational devices and applications. The various interaction modes in multimodal systems often involve natural forms of human behaviour, e.g. voice, touch, gaze, hand gestures and body movement. The user often has the option to combine these or choose between them, depending on the task being performed or the condition of the interaction (e.g., indoors vs outdoors, on-the-go, etc.). Multimodal interaction is about natural human behaviour, choices and flexibility.
Take one example from the video (link above): “What can I make with this” (while showing the system a chili pepper). The system is multimodal in that it processes both combined input signals: the user’s voice query, and the shape, colour and size of the food item. It uses both speech-recognition and object-recognition technology. While monomodal voice queries such as “what can I make with a chili pepper” or “show me recipes that use chili pepper” could have been possible, the shorter multimodal command felt somehow more natural or spontaneous, and returned accurate results.
Tablets are multimodal: you can interact with them with your voice, touch and/or an e-pen

We have researched alternatives to keyboard-and-mouse PCs for as long as we have had them
The first efforts to develop and test multimodal systems took place during the 1980s and 1990s. These works coincided with the ongoing efforts to improve speech recognition technology and integrate it into different professional domains and applications.
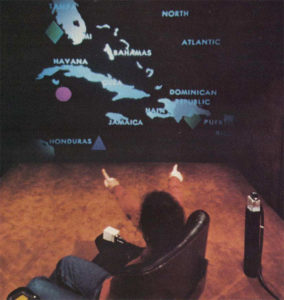
“Put that there”
One of the earliest works on multimodal interaction is probably Bolt’s famous “Put that there” experiment in 1980, which examines some of the advantages of combining different input modes such as voice and hand gestures. In his seminal paper, Bolt describes an experiment in which the user issues voice commands to a system while pointing to carry out different tasks such as creating, modifying and moving objects. Saying “put that there” while pointing would be easier and more effective than saying, for instance, “put the small purple circle at the top right corner of the screen”. The hundreds of studies that followed have demonstrated the many advantages of multimodal systems as compared to monomodal systems or keyboard-based interfaces, both from the users’ perspective and from a computational perspective: from increased productivity and flexibility to a better user experience; from higher accuracy to lower latency.
Improving support for human translators’ cognition and performance
The major impetus for developing multimodal interfaces has been the practical aspects of mobile use. In our day, among the most concrete examples of commercial multimodal interfaces are tablets and smartphones, which are basically voice-and-touch-enabled (but include as well other recognition-based technologies such as gesture, gaze and facial recognition).
However, the interest in multimodal interaction goes well beyond mobility:
“Ultimately, multimodal interfaces are just one part of the larger movement to establish richer communications interfaces, ones that can expand existing computational functionality and also improve support for human cognition and performance […]. One major goal of such interfaces is to reduce cognitive load and improve communicative and ideational fluency.” ( Sharon Oviatt)
Such support for improved cognition and performance is what human translators need from their technology tools; not the opposite. At InTr Technologies, inspired by successful case studies in many professional domains and day-to-day applications (and what we have experienced with our own senses), we have investigated and continue to investigate how multimodal input could enhance human translators’ capabilities and improve their performance and ideational fluency.
How do you envision the future of translator-computer interaction?
If you are a professional translator and, like hundreds of thousands of others around the world, are experiencing frustration with the paraphernalia in your toolbox, or even physical discomfort or illnesses with the traditional desktop PC environment, you can organically introduce multimodal interaction to your work, and harness its power and benefits. You may draw some inspiration from how tech giants envision human-computer interaction in the years to come. (Try searching “future vision 2020” on YouTube and you will find many more examples of how our work and life could look like in the next decade or so). Much like artificial intelligence, most of these “futuristic” technologies are disruptive rather than evolutionary. They do provide us, however, with hints about how else we could be working and collaborating in translation (beyond the traditional picture of the lone individual typing and clicking all day in front of a desktop or laptop computer ̶ and with a pile of dictionaries).

You may have a dream work environment in mind. You may have examples of successful multimodal interaction in translation (say, if you use voice-recognition software, cloud-based applications and/or mobile devices while you work). You may be just curious to learn about how translators have used multimodal interaction in a lab or a real-life work environment, or what our research has in store for you. If you are any of these translators, or a stakeholder in the language services industry, talk to us ̶ in English, French or Spanish!
Recognition-based technologies are more and more robust, mobile devices more ubiquitous, and cloud services more reliable. We have the ingredients on the table. Now, what can we make with these?